IPython/Jupyter notebooks have built-in "pretty" formatting of dictionary (and related) constructs. For example, take this messy, nested dictionary construct:
data = {
"name": "Alice","city":"New York", "isMarried":
True, "hobbies": ["reading", "running",
"painting"], "address": { "street":
"123 Main St", "state": "NY"
}, "pets": [ { "name": "Fluffy","type" :"cat",},{
"name": "Rover","type": "dog" } ]}
Use that value as the last expression of a notebook cell, and it will be rendered automatically in a more readable format:
data
That's not only more readable, it's also still valid Python code, ready to be copy-pasted elsewhere.
Can I haz JSON?¶
However, this representation has some drawbacks too. While it looks quite a bit like JSON, there are some subtle incompatibilities, for example: strings use single quotes by default (JSON required double quotes) and boolean values are title-cased (JSON uses lower case). This can be quite annoying if you have to transfer these kind of data dumps to tools that only understand JSON.
In this notebook I'll explore some solutions and tricks
to automatically get JSON-style formatting for this kind of data,
without having to manually sprinkle json.dumps() calls all over the place.
Automatically try a JSON dump¶
In this first trick, we override the IPython's "text/plain" formatter,
which is used by default for rendering of notebook cell results,
unless the data type provides a custom visualization hook
(e.g. by defining _repr_html_() or something alike).
We first try JSON serialization (with indentation),
which will work for data constructs that only contain basic Python data types
like dicts, lists, strings, integers, etc.
If it fails because JSON serialization is not supported for some part of the data,
we fall back on the default behavior (prettified Python repr).
import json
import IPython.core.formatters
class JsonDumpTryingFormatter(
IPython.core.formatters.PlainTextFormatter
):
def __call__(self, obj):
try:
return json.dumps(obj, indent=2)
except TypeError:
return super().__call__(obj)
_ipy = IPython.get_ipython()
_formatters = _ipy.display_formatter.formatters
_formatters["text/plain"] = JsonDumpTryingFormatter()
If we now trigger the formatting of our original data value,
we get its JSON serialization (note the double quotes, and lower case true boolean):
data
Values containing data types that are not supported by default
in json.dumps (e.g. Python sets, or custom classes),
show up in classic Python repr-style:
class Pet:
pass
{"fib": {2, 3, 5, 8}, "scruffy": Pet()}
Some additional type coercion¶
If allowed or necessary, it is also possible to add a bit of type coercion (e.g. convert sets to lists), like so:
import json
import IPython.core.formatters
class JsonDumpTryingFormatter(
IPython.core.formatters.PlainTextFormatter
):
def __call__(self, obj):
try:
return json.dumps(
obj,
indent=2,
default=self._json_default
)
except TypeError:
return super().__call__(obj)
def _json_default(self, obj):
if isinstance(obj, set):
return list(obj)
raise TypeError(f"Unsupported type {type(obj)}")
_ipy = IPython.get_ipython()
_formatters = _ipy.display_formatter.formatters
_formatters["text/plain"] = JsonDumpTryingFormatter()
See the set to list conversion in action:
colors = ["red", "green", "blue", "red", "blue"]
{"colors": set(colors)}
Enable the built-in JSON visualisation on dicts, ...¶
IPython/Jupyter also has built-in functionality to visualise JSON structures as an interactive tree where you can expand and collapse nodes. You can enable that visualization as the default rendering of dicts and lists with this snippet:
import IPython
_ipy = IPython.get_ipython()
_formatters = _ipy.display_formatter.formatters
_json_formatter = _formatters["application/json"]
_json_formatter.for_type(dict, lambda obj: obj)
_json_formatter.for_type(list, lambda obj: obj)
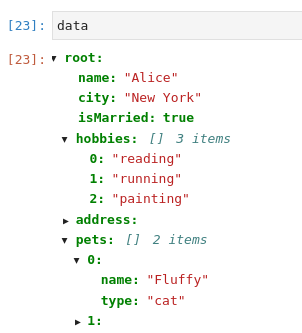
Unfortunately that widget seems to get corrupted when exporting to HTML for this blog, so I have to resort to a screenshot to illustrate it in action on our original data dictionary: